日本語の縦書き文章を OCR するコツ
· 3 min read
前置き
Windows11 に標準で搭載されている snipping Tool には OCR 機能がある。この OCR 機能は極めて優秀で、市販の OCR ソフトよりも勝っているのだが、一つ、大きな欠点がある。
それは、日本語の縦書き文章を OCR 処理させると、行が入り乱れてしまうという問題。しかも不規則に乱れる場合もあるので、後から機械処理で訂正することもできず、人手で直す必要がある。これはダルい。
で、その対策を見つけたので記録しておく。
Microsoft は何事もユーザーに押し付けるという、傲慢かつ独りよがりな社風なので(Apple は Apple で鼻につく社風なのでイヤ)、縦書き文章の OCR の改善も期待できない。当面は以下の方法で凌ぐしかない。
縦書き文章を OCR するコツ
縦書きの日本語文章の画像を、左に 90度回転させてから OCR させる。
思いついたときには、自分でも「まさか。そんな雑な方法でいけるかよ…」とは思ったが、試してみたら これで いけた。
具体例
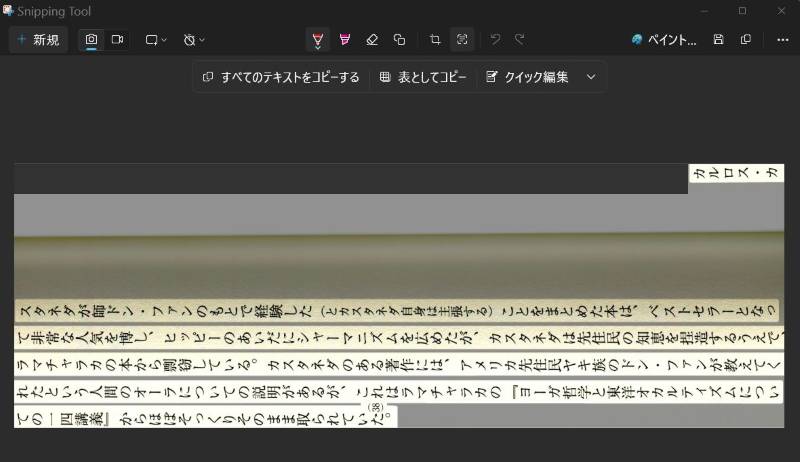
OCR
スタネダが師ドン·ファンのもとで経験した(とカスタネダ自身は主張する)ことをまとめた本は、ベストセラーとなっ
て非常な人気を博し、ヒッピーのあいだにシャーマニズムを広めたが、カスタネダは先住民の知恵を捏造するうえで、
ラマチャラカの本から剽窃している。カスタネダのある著作には、アメリカ先住民ヤキ族のドン·ファンが教えてく
れたという人間のオーラについての説明があるが、これはラマチャラカの『ヨーガ哲学と東洋オカルティズムについ
(38) ての一四講義』からほぼそっくりそのまま取られていた。
カルロス·カ
冒頭の「カルロス·カ」だけ、最後になっているが、これは英文 OCR でも図の部分などで時折起きる現象なので、許容範囲。
(2025-05-29)